The Babble
Podcast by NotebookLM

New Features, Tools, and Our Podcast: The Babble
The Babble: Residual Stream's Podcast by NotebookLM
Before diving into Neuronpedia updates, we're introducing The Babble, a AI-hosted podcast generated by NotebookLM, where each episode is based on a Residual Stream post - including this one. It's a light and casual way to consume Neuronpedia updates - check it out and let us know what you think!
🔊 Ep. 1 - Open Sourcing Neuronpedia (Previous Post) - [Apple] [Spotify]
🔊 Ep. 2 - A Bunch of Updates + Podcast (This Post) - [Apple] [Spotify]
Podcast Links: Apple Podcasts | Spotify | Podcast RSS
Of course, you can still subscribe to our regular text RSS, which is manually written by a human.
TL;DR
- New Stuff
- TopK Search By Token: Find, filter, and sort top features/latents by token. [Demo] [Try It] [API]
- Matryoshka SAEs: Trained by David Chanin, absorption paper author. [Demo] [Browse] [LW] [HF]
- Probity: Python library to generate and use probes on Neuronpedia. [Github] [Demo]
- New Auto-Interp Models: GPT-4.1, o3/o4-mini, Claude 3.7 Sonnet/3.5 Haiku. [Example]
- Domain: Neuronpedia supporter @sheikheddy generously donated residual.stream. Thanks! 🤩
- Stuff We're Working On: Making Development Suck Less, Docs, Tests, etc. [Github]
- Asks: Feedback, Feature Requests, Collaborations. [Contact]
Feature: TopK Search By Token
[Try It: Click "Random"] [API + Docs]
Background
Previously, there were two ways to search AI internals. You could "Search Explanations", which searches all the auto-interp labels for latents/features. You could also "Search via Inference", which would give you the top features by activation that fired for a custom phrase. But this method of searching was sort of annoying if you only cared about specific tokens (you had to manually filter afterward).
Description
Today, we're adding "TopK Search by Token", which is similar to Search via Inference, except it allows you to quickly zoom in on the top activations for each token, instead of the whole text. It also supports better filtering and sorting. A list of functionalities:
- Custom Text: Enter whatever text you want, or use a random preset to quickly get started.
- Per-Token Detail: Hover over the tokens in the results to see the top activating features/latents for that token. Click a token to lock/unlock it in the UI.
- Per-Feature/Latent Detail: Hover over a feature/latent to see which tokens activated it. Click a feature/latent to get the feature dashboard popup, where you can test and steer that specific feature without leaving the results.
- Filtering and Sorting
- Filter By Density: Some features/latents fire too frequently, adding too much noise to results (for example, a feature that fires of "beginning of sentence"). You can use the Density Threshold slider to hide features that activate too frequently.
- Filter Out BOS: The BOS (beginning of sentence) tokens can have such high activation values that they drown out other results. Use "Show/Hide BOS" to turn these off.
- Sort by Frequency, Max Activation, and Density: By default, the results sort by Frequency (number of tokens that activated on the feature/latent).
- Sharable Results: Search results automatically update the URL, so if you want to share the results, just copy the URL to share it with someone.
- API: This functionality is available via our API - see docs and pregenerated code here.
The main downside of using TopK Search By Token is that you are limited to one Source (set of features/latents) at a time. For example, you cannot select all layers of a Gemma Scope SAE - you must choose a specific source, like 20-GEMMASCOPE-RES-16k.
Demo! TopK Search By Token
Clicking the demo link above, we see the Search TopK by Token results for a text about the Magna Carta. To the right, we see the tokens at the top and the most frequently occurring features below that. The top feature fired on 14 tokens, and it was about "historical references" - which seems to match our text. The video demo below shows some of the other functionalities, like zooming in on a single token, filtering, sorting, etc.
Data Release: Matryoshka SAEs (In Progress)
[Browse the new SAEs] [LessWrong] [HuggingFace]
Matryoshka SAEs (Nabeshima, Bussmann, Leask) attempt to overcome some of the weaknesses of sparse autoencoders (Chanin) by training on a mixture of losses, each computed on a different prefix of the SAE latents.
We're adding two sets of Matryoshka SAEs trained by David Chanin. We intend to have all layers available by next week - currently layer 12 of gemma-2-2b and layer 20 of gemma-2-9b are completed and uploaded.
We ran and uploaded the SAE Bench (Karvonen, Rager) Feature Absorption eval on the gemma-2-2b@12-res-matryoshka SAE, and found a mean full absorption score of 0.05 and mean number of split features of 1.12 - similar to scores of the closest SAE Bench Matryoshka SAE.
Demo! Catching Z using a "Starts With Z" Latent
One task that sparse autoencoders notably fail at is exhaustively finding features that start with a certain letter, due to feature absorption.
Here, we use the new "Search TopK By Token" on the gemma-2-2b@12-res-matryoshka SAE. We enter a bunch of words that start with 'z', and find a latent in a Matryoshka SAE that seems to fire on "starts with z".
⚠️ Importantly, we increased the "density threshold" of the search so that we can find features that are more dense, because we expect a general "words that start with z" latent to be active in more texts than a specific latent like "zebra".
But that's not an exhaustive test. So, we took the experiment further by using a list of 427 English Scrabble words that start with z and Neuronpedia's activation testing API to test every z-word to see if they activated on this latent - and they all activated! [Colab Notebook]
Of course, this does not mean we have solved feature absorption or other issues with SAEs. But by providing the tools and data, we allow anyone to quickly spin up experiments to make real advances. And remember, now that Neuronpedia is open source, you can do all this (and more, if you customize) on your own data too.
New Library: Probity - Create Probes, Test/Share on Neuronpedia
Probes are relatively inexpensive and have been found to outperform SAEs in some tasks. Probity is a Python library (created by Curt Tigges, Decode/Neuronpedia's science lead) that lets you easily train probe of different types (linear, logistic, PCA, etc) and analyze them. It's designed to be easy to use, with multiple tutorials and a documented pipeline to speed up your research.
In the [first Probity demo], we train a probe for "positive sentiment" for GPT2-Small, and upload it onto Neuronpedia, where we steer it toward a positive restaurant review:
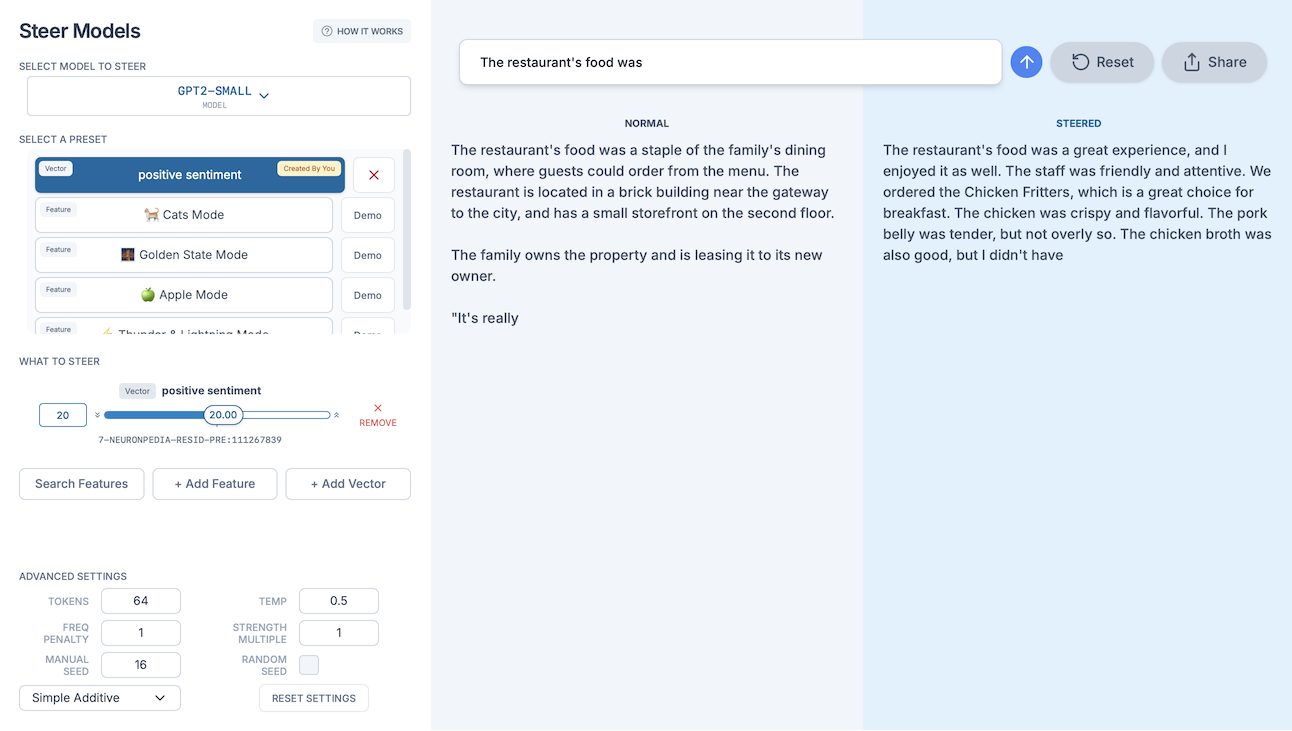
Once uploaded to Neuronpedia, these probes can be shared, steered, and embedded into your websites/posts, and more. You can even upload your own activations via API for a custom dashboard! (Tutorial soon.)
Auto-Interp Models: GPT-4.1, o3, o4-mini, Sonnet 3.7 / Haiku 3.5
In case you have been living under a rock, they're now shipping new frontier models on days ending in "y". We now allow you to leverage the intelligence of near-AGI models like o3 and Sonnet 3.7 to auto-interp your Matryoshka latents, or AxBench concepts, or DeepSeek R1 features, or whatever the next breakthrough is.
⚠️ Warning: Be sure to enable the models in your OpenAI project limits page! If not, you will get an error because your API key won't have access to the model. Note that OpenAI takes some time to sync this setting (>30 min) once you've enabled it.
Working On: The Developer Experience + More
Currently, the process of getting set up to do some Neuronpedia is, in a word, crap. For example, good samaritan @shayansadeghieh recently helped us debug an issue that another user was experiencing, but it was not obvious at all how to properly set up and call the Neuronpedia inference server to reproduce the issue. Fortunately, they figured it out - but we will not always be so lucky.
Why is this so hard? It's partially because Neuronpedia is many different things in one, and partially this is because we can do so much more on documentation, examples, tests, and abstractions.
{kind=link}
We're focused on the latter (while trying to move forward on new features), because that's what we can change. By making Neuronpedia development more accessible, we hope to multiply our impact and decentralize its progress. In the mean time, please help highlight and report issues you run into when trying to set up Neuronpedia.
Our special thanks recently to Anthony Duong (ARENA alum) for doing extremely useful engineering not only for fixing bugs, but also cleaning up code and dogfooding our development process!
Ask: Float Your Idea in the Residual Stream
Neuronpedia has been very fortunate to work with both independent researchers as well as larger labs and organizations. We have a few things in the pipeline that we're quite excited about, and we would like nothing more but to help to you spread your research and making it accessible and experiment-able to everyone. No matter how small or how wacky your idea is, let us know and we'll make the collaboration happen.
That's all for this week - see ya'll next time!